大厂再造AI云,洗牌三年结束,看谁下牌桌
原创 亲爱的数据 亲爱的数据
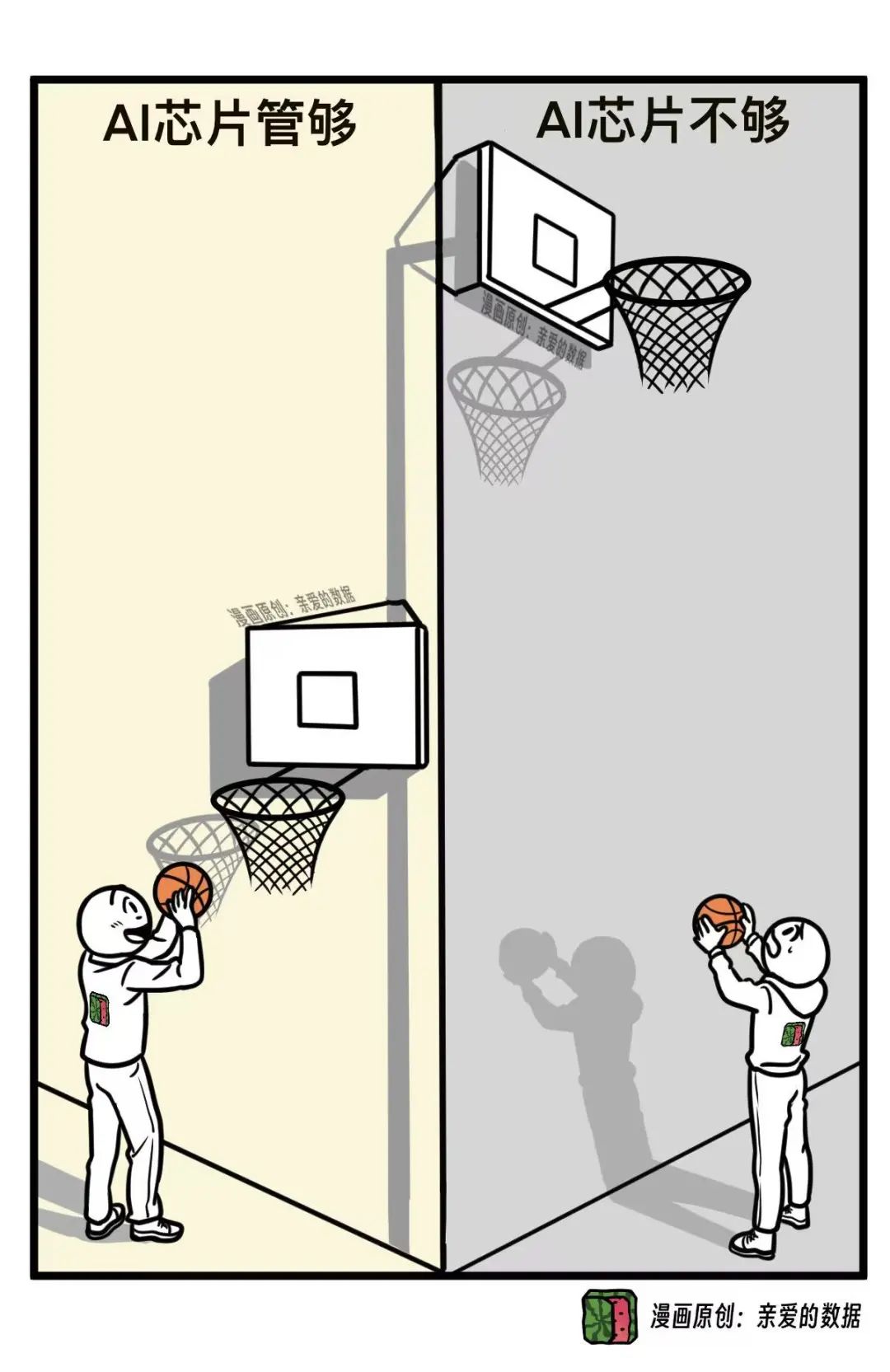
都看到了,校准原理市场上,
字节扫货式采购,
阿里3800亿元,
百度自建3万卡昆仑芯集群,
在芯片上,
大家把吃奶的劲都使出来了,
家底都拿出来了。
该上桌的都上桌了。
Qwen3也快发了,
我拿到的料是:
一方面参数规模还在变大,
另一方面MoE的设计还在变。
一开头,我做个简单的区分,
云厂商将会分两种,
传统云厂商,AI云厂商,
前者经过多年发展,
他们的规模已经发展的非常大了,
国外有AWS,微软云,谷歌云;
国内有,阿里云,字节跳动火山引擎,
百度云,华为云,腾讯云,国有云等等。
今天就聊这两类家伙,一新一旧。
当下,依然是传统云厂商“一统天下”,
不过面临AI云的严峻挑战。
美国讨论这个话题,也AI云和GPU云混着叫。
什么能短暂干掉技术壁垒?
答案是“GPU缺货”。
当前市场对算力的需求远远超过了供给,导致价格居高不下。
即便算力使用的效率低下,依然有人愿意买单。
“缺”急乱投医,有总比没有好。
那些单纯出租GPU算力,无需复杂的调度引擎或优化算法,
只要满足客户对GPU芯片的需求,
只要有足够的硬件资源(GPU芯片),即可获利。
这不是我的推论,这是我看到的事实。
许多技术壁垒被暂时掩盖,“有资源”比“有能力”更重要。
这一部分生意,侵蚀了云厂商的利润,
好在这是一部分,不是全部。
好在这是短期内,不是长期。
我打一个比方,我家里有矿,
哪怕我的采矿技术落后,
我仍然可以通过出售原矿获得巨额收益。
道理是这么个道理,
这种时间段的形势是:
技术壁垒退化为资本壁垒。
有没有有可能你储备了足够多的武器,
就赢得战争?

AI芯片够了,下一步呢?
我的答案是AI云崛起。
不过,有可能头部云厂商可以自己打败自己,
就好比在香港影史上,
《破地狱》的票房打赢了《毒舌律师》,旋转编码原理
主演都是黄子华,
他自己打赢了自己。
美国有不少GPU云品牌,列21家:
CoreWeave
Crusoe
together.ai
Nebius
Lepton AI
Lambda
Scaleway
SMC
Tensorwave
RunPod
DENVR DataWorks
DataCrunch
HOT AISLE
Shadeform
Vast.ai
Massed Compute
PrimeIntellect
IrisEnergy
GMI Cloud
Akash
GPU.net;


毫不意外,美国的GPU云公司数量不少。
这篇核心不是在对比中美,
此处按下不表。
我主要想说:
AI云门槛低比传统云计算的门槛低,
以及门槛低引发的问题。
第一,低门槛吸引了大量投机者。
很多创业团队甚至传统IDC厂商,
开始“堆卡做AI云”。
他们可能没做过复杂的分布式系统,
也没有构建高效推理引擎的经验,
但看着大模型爆火就匆匆下场。
这类公司大多只是把GPU硬件“租”出来,
而非提供系统级创新。
第二,忽视基础软件,
陷入“买卡=服务”的误区;
资源利用率极低,体验差,
拉低行业口碑,客户骂娘;
第二推理服务商品化太快,
技术壁垒还没拉起来;
AI云现在的主战场是推理,
许多企业提供模型即服务(MaaS),
前期,低质GPU云厂商,
可能靠开源模型+容器就能上线。
AI云的门槛“相对”低,不意味着它容易做,
更不意味着每个进场者都能做好。
一旦太多低质玩家,
那就会是“只懂租卡,不懂架构”。
DeepSeek“开源七天乐”里的3FS等这些东西,
是为了从软件角度压榨硬件性能,
而这些正是大多数低质GPU云厂商不具备的。
因为有了开源的deepseek,
很多厂商觉得自己又可以爬起来了,
开始搞推理。

美国GPU云的厂商名单不短,
高质量玩家藏身其中。
投资人:投投投,让我投。
继续聊,门槛低这件事。
不要误会,这个低,你看和谁比。
这里我说它低,是和传统云厂商比。
说起传统云厂商的技术含量,
那技术故事真的是后劲十足,
谭老师我连续七年参加阿里云云栖大会。
那真是一段黄金岁月。
也就是说,传统云厂商(CPU通用云)壁垒,
是经年累月构筑,
大量人力财力堆积而成,
是技术的成功,也是规模的成功。
人家AI云的技术含量很有的,
只是低质量厂商的技术含量不多。
只是复杂的维度不同。
这世间,有的是AI云的大佬,
用高效的推理引擎和底层软件架构,
来提升性能和降低成本。
要知道,构建一个高效,
可扩展的LLM推理系统并非易事,
尤其是在满足大规模企业级需求时,
软硬件的深度集成和优化至关重要。
想超越现有大模型派系的竞争者,
如DeepSeek,
不仅需要强大的技术团队,
还需要创新的思维来突破传统推理架构的局限。
这一系列的,独特的挑战客观存在。
然而,但从软件的角度来看,
GPU云比传统的CPU通用云更容易做出来。
我再次强调,此容易,非彼容易,
而今的GPU云,也有很高的壁垒,
但没有CPU云当年的维度复杂。
这对竞争者来说意味着什么?
答案是,机会。
在“新旧交替”之际,
聊聊,哪些难点消失了?
第一,
从软件角度来说,GPU云比通用云更容易操作,
主要是因为它们的功能和服务相对较为简化。
此话怎讲?
传统云服务商(如AWS、Azure)的云服务是全栈式的,
提供从计算、存储到数据库的多种服务,
用户需要处理复杂的系统集成,
服务内容非常广泛。
而GPU云的服务和功能相对单一,
在软件管理上相对简单。
传统云计算中,用户可能需要管理一个复杂的应用堆栈,
包括前端、后端、数据库、
缓存服务、身份验证、支付接口等。
这些系统需要高度集成。
在GPU云中,主要的关注点是提供算力,
特别是GPU加速的计算。
不涉及到用户的全栈应用开发。
它不需要处理像日志管理、
消息队列等传统云平台所必需的服务。
传统云平台就像“滴滴打车”,
你不仅仅要把人从A地送到B地,
还涉及到处理车辆调度、订单管理、
支付和评价等复杂的后台服务。
那这块AI云有什么技术含量的事情可做呢?
芯片架构是多样的。
AI云面临的复杂硬件架构和多芯片的适配问题。
硬件架构特性对推理系统的性能影响深远,
芯片架构会改变推理系统的架构,
需要推理引擎与硬件的高度集成。
另外,芯片的互联与协作,
如果能够回避掉多芯的难题就好了,
但是,国内厂商恐怕更得正视这个难点。
此时,我只能无情地写下:
多个芯片在云环境中协同工作时,
如何高效地管理它们之间的数据传输、
负载均衡和资源调度,
是GPU云面临的技术挑战。
第二,
数据库是传统云厂商利润最丰厚,
客户粘性最大的业务,
而GPU云通常只提供计算资源,
并不涉及存储和查询等复杂功能。
用户将计算任务提交到GPU云,
GPU云的目标是加速计算任务,
而数据本身可存储在其他地方,
高带宽的网络快速传输。
对于大多数用户(除了极少数大规模用户),
数据的位置并不是那么重要。
存储本身在AI中所占的成本并不高。
那这块AI云有什么技术含量的事情可做呢?
可以补充阅读这篇:
《》
不过,对AI来说,数据的存储本身并不复杂,
但数据从存储到计算节点,
传输速度和读取速度会直接影响效率。
比如,DeepSeek写了一个专门设计的,
高吞吐的数据加载系统(名叫3FS),
它不是传统意义上的文件系统,
解决的是数据读取慢。
也就是,存哪我不管,成本低就行,
但我要求数据传输得快。
第三
传统云用虚拟机来分割资源,
也就是虚拟化CPU算力资源来服务多个用户。
每个虚拟机可能运行在不同的操作系统上,
资源共享。
对于GPU云来说,
由于客户通常需要的是专用的计算资源,
虚拟化层并不是必需的。
客户常用的是专门分配的计算节点,
GPU云更像是把“整车”直接交给你,
而不是将其分成多个虚拟“座位”。
“滴滴打车和整车租赁”这个比喻,
以前大佬朋友圈写过,
我借花献佛,
希望没有曲解大佬的意思。
我从技术,聊回市场,聊回竞争,聊回行业巨浪。
字节扫货式采购,阿里投入3800亿元,
百度自建3万卡昆仑芯集群。
眼睁睁看,大厂能梭哈给芯片的都梭哈了,
除了芯片,你观再察大厂搞AI的决心,
看它调不调组织架构,
动不动绩效。
腾讯调了组织架构,字节动了绩效。
某厂虽然是把一年的芯片订单都下了,
但优先给了C端,没有优先给云。
某厂虽然自己造芯很猛,
但是无奈上面的基础大模型实在不行,
换帅了。
我就反问一句,如此高强度的竞争,
以“基模+云+芯片,三位一体”的方式打。
洗牌三年内结束,是不是都说长了。
云大厂三年内见分晓,看谁下牌桌。
无论CPU云,GPU云,
若云厂商大模型缺位,
其他类型的大模型技术拥有者会带动生态迁移。
更大的画面是,谁掌握了大模型,
谁就可以定义未来的科技生态。
不过,生态从早期到成熟,是一个漫长的过程,
那天和一个朋友聊,
汽车从第一天上路到世界流行,
过程也挺漫长。

(完)

原标题:《大厂再造AI云,洗牌三年结束,看谁下牌桌》

发布评论