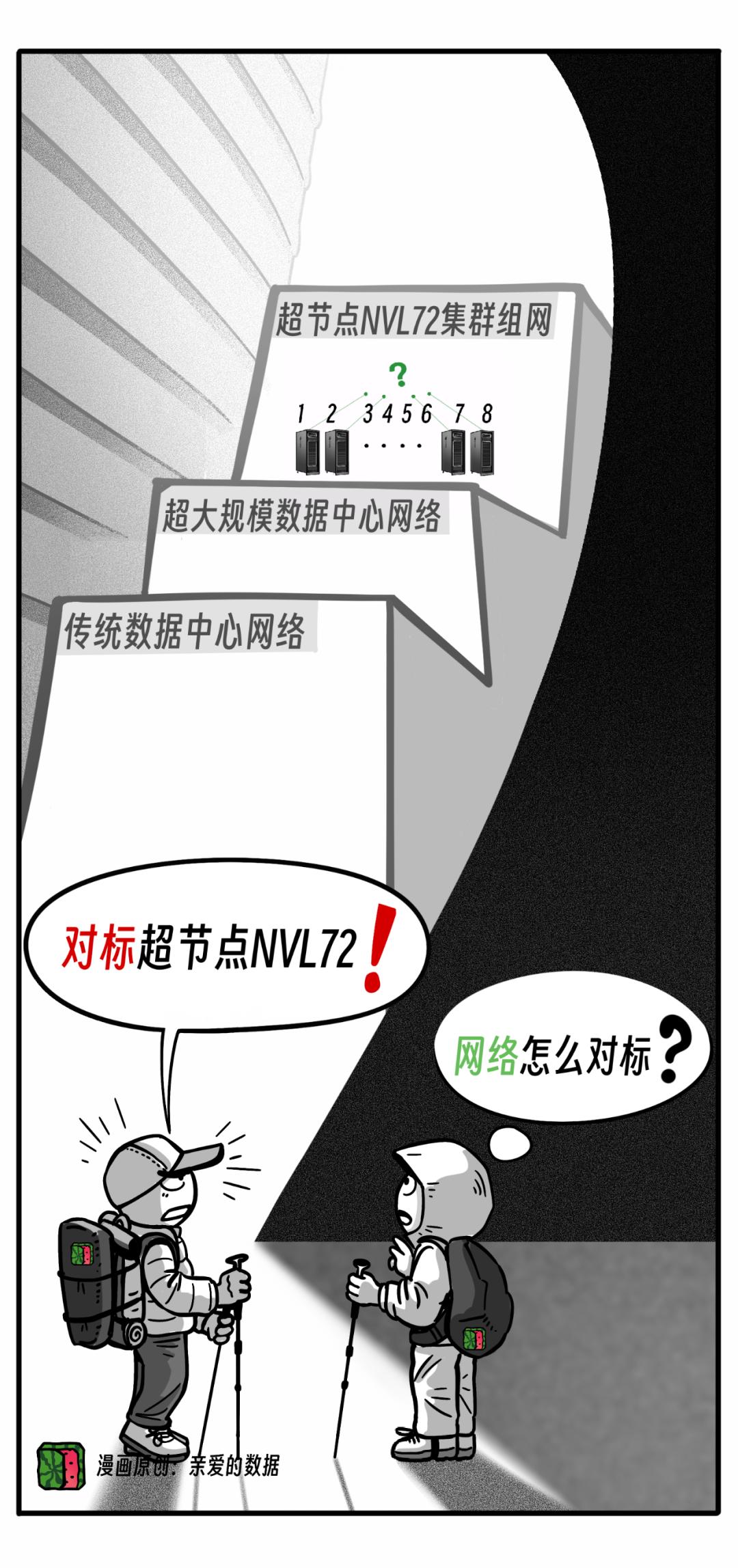
对抗NVLink简史?10万卡争端,英伟达NVL72超节点挑起
原创 亲爱的数据 亲爱的数据

先说重点,
GPU计算不能等,hygromycin建立稳定细胞系的原理网要好。
到底用哪种网,
这个问题成了关键。
而且,还有人误会网络不重要,
我得知:
一家国产知名大模型厂商,
就不说哪家了,
买了英伟达一万张卡,
配的PCIe接口。
送命不至于,
就是吃亏。
我判断:
2024年全球头部GPU技术路标:
用超节点连起的10万卡GPU集群。
那么问题来了,卡之间的连接,
用什么网?
我还判断:
英伟达超节点(NVL72)引领下一轮组网架构,
除了英伟达以外的玩家,
他们往往被称为“非英伟达厂商”
该如何应对?
言下之意明了,
AI网络进入大争之世,
各自为战,还是联盟合作?
这篇文章将探讨,
多方玩家竞争与合作的可能。
目录:

(一)机内机外“过时了“?

故事开始了。
无论别人信不信英伟达垄断,
反正我信了。
当然可以说得保守点:
“有垄断之嫌”。
英伟达垄断了计算,
那是否垄断了网络?
在大规模GPU相互连接进行计算的情况下,
计算与网络紧密交织,
性能不再是一个单一的概念。
英伟达服务器内部网络是封闭玩法,
谁也不能自造一个网络,
跟英伟达的拼起来用。
俗称“拼桌。
不就是传输个数据包,还分派系了?
真是如此,
没办法,
科技厂商天然偏好各自为战,
因为终极都追求“垄断”。
如果哪天不这样了,
一定是有什么强大力量,
让他们痛苦了。
这是我一开始的想法,
只看到了其中一层,
现在我有了更深的理解,
后面会讲。

你看,数据中心里的AI网络,
网络分两种。
机内和机外。
不得不服气的是,
短短几个月,
我发现这种说法已经过时了。
没办法,技术又迭代了。
一个服务器是4卡8卡GPU的时期,
可以这样说。
然而,当NVL72这种超节点产品来了,
这个说法就不准了。
“机内机外”容易造成误解。
也就是,“机内机外”过时了。
这意味着,
一场新纷争悄然揭幕。
两句话说不清,
展开细聊。

话说回来,
GPU4卡8卡的时候,
机内互联,集成度高,
网络速度非常快。
打个比方,
一个服务器好比一间教室,
坐8个学生,互相传作业
相当于,8张GPU卡用NVLink相连。
然而,想和其他教室传作业,
网速就会慢。
有多慢呢?
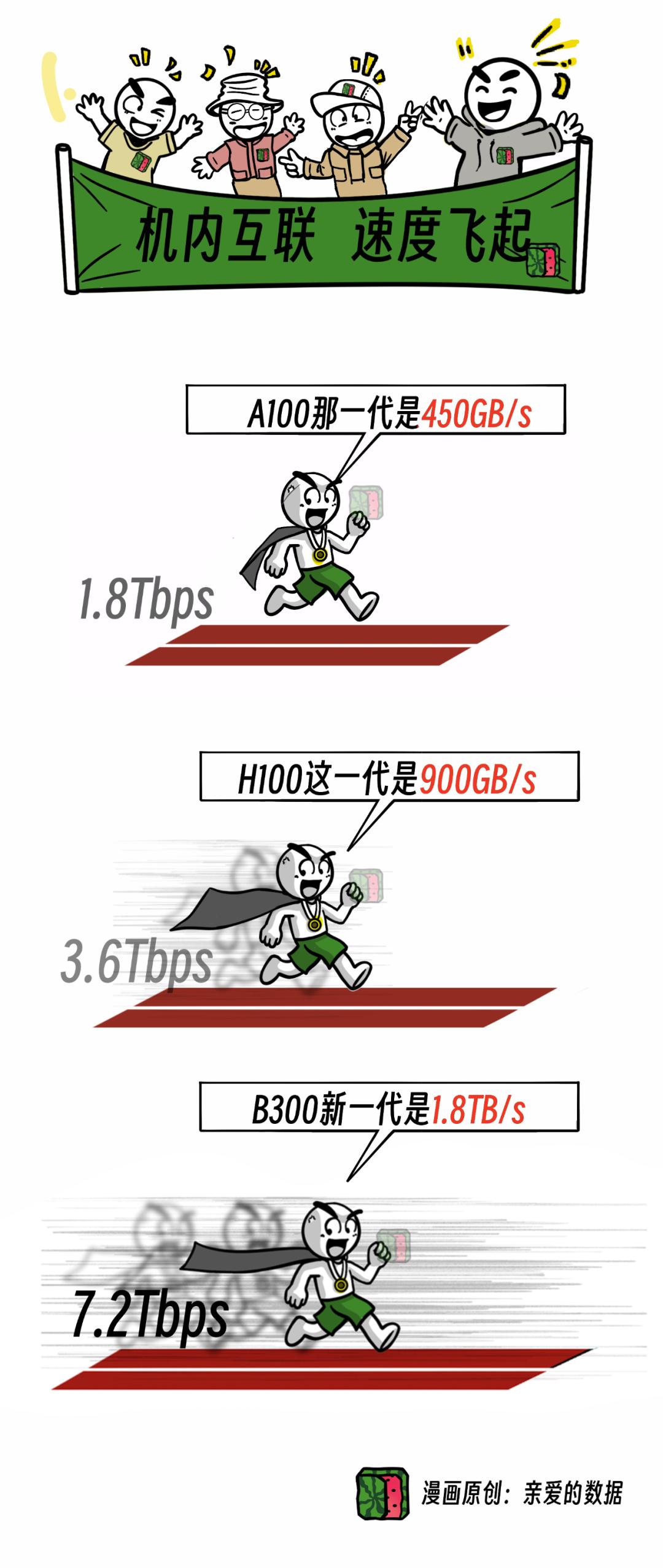
服务器外的网络(机外网络),
比机内网络慢了一个数量级。

除了快慢,
还有价格,
机内网络比机外网络贵多了。
结果很清楚,
英伟达赚了好多钱。
强需求,
又推着GPU了上了一新台阶。
英伟达拿出了产品GB200 NVL72,
下文简称NVL72。
这个产品一出现,
就引领了一个新方向,
在计算集群中,
每个节点通常包含多个 GPU 和处理器。
这里提到的 " NVL +数字" ,
指的是一个超大节点中GPU数量。
NVL36的节点有36个GPU。
同理,NVL576的节点有576个GPU。
让人生气的是,
国产暂时没有能比肩的。
不过谭老师我可以喊话国产厂商:
“等着用,搞快点”。

英伟达NVL72的机柜就像一个大冰箱。
内部也挺复杂,
有72个GPU分别放在18张计算卡上,
一个计算卡,其实就是一个Tray(托架)。
而一张计算卡,
相当于一台服务器。
这样,每张计算卡里有4个GPU。
口算4 X 18=72,
相当于装了72个GPU。
网络也非常好,
72个GPU工作起来像一个。
这个东西不能再叫服务器,就不合适了,
那就叫超节点吧。
于是,新问题来了,
请问,这个超节点里面72个GPU用的什么网络连接?
答案是选A,还是选B?
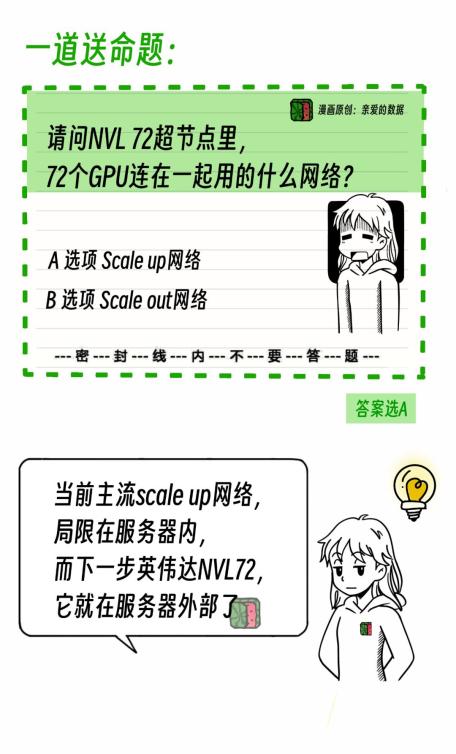
没搞错吧?
以前,机内和机外网络。
以前,8个以上GPU就是Scale out网络,
现在72个GPU了,
理应仍然是Scale out网络。
为什么是Scale up网络?
当超节点走进数据中心组网,
技术变了,争议来了。
商机也来了。
(二)题好难
论单词难度,
Scale up网络,Scale out网络
是高中英语考试的难度,
论技术难度,
一下冲到了阿里P7。
题这么难,都是NVL72造成的。
替我问候一下它。
技术上的变化到底是什么呢?
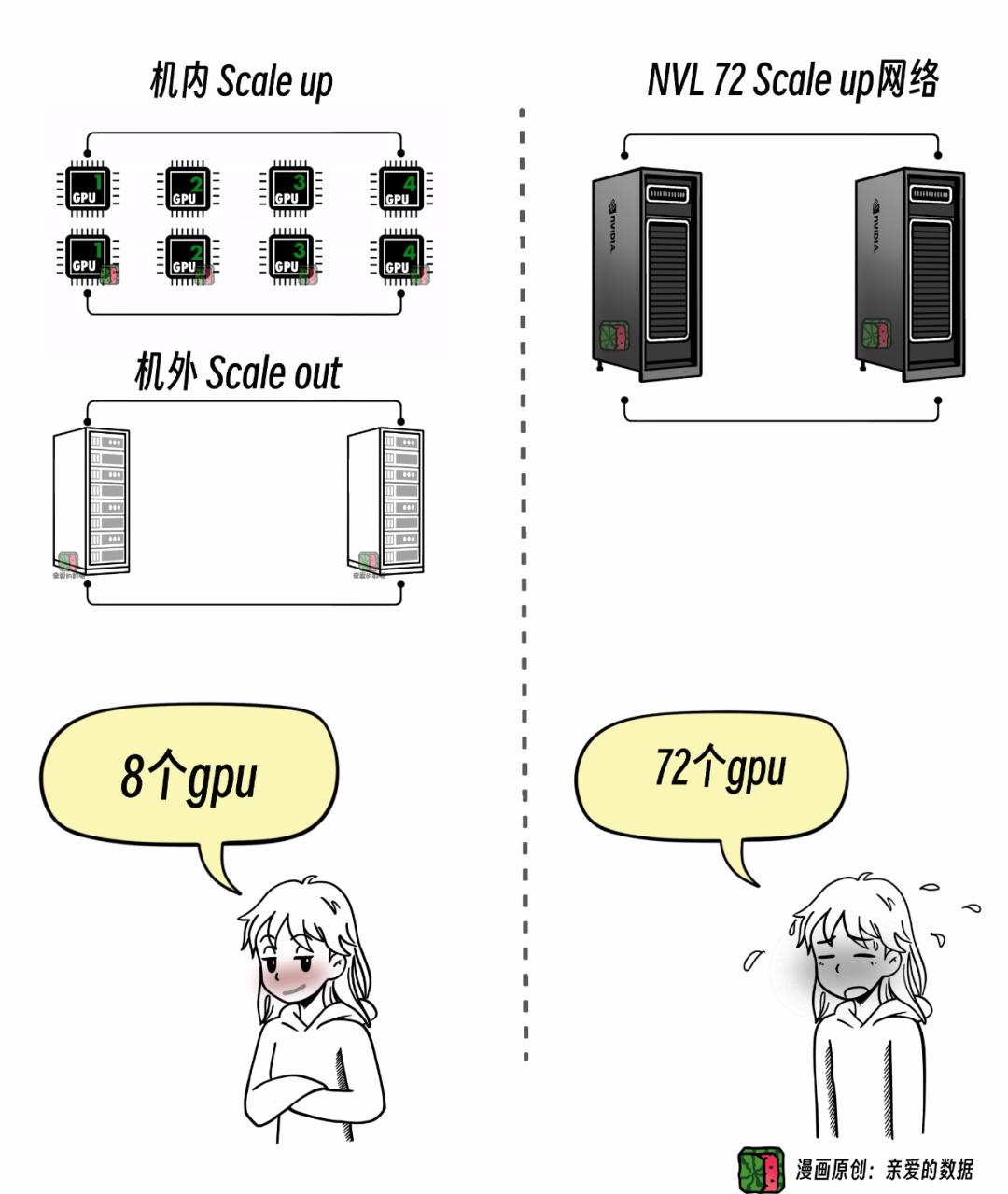
以前,Scale up网络局限在服务器内部,
现在,NVL72里面明显用到了服务器外面的网络,
所以,是Scale up网络。
不只叫法变了,
本质是网络结构变了。
最初一个服务器有8个GPU,
所有GPU在同一个操作系统 (OS) 内,
这使得它们彼此访问内存变得很自然,
类似于一个“共享内存”的环境。
当系统扩展到 72个GPU 时,
这些GPU要被分散到18个操作系统中,
但得益于硬核网络支持,
它们分布在不同的操作系统 (OS)上,pcr仪的原理 应用及发展趋势
且能跨多个操作系统 (OS)来进行操作。
比如,第一个操作系统 (OS),
直接“访问”第 18 个操作系统 (OS)的内存。
所以,即便扩展到72个GPU,
继续叫它Scale up网络。
叫法并不是重点,
重点在于要设计新网络结构,
部署新的Scale up网络的设备,
这些都要花钱。

另一方面,
硬件有变化,
GPU有72个,
但这个说法不准确,
应该是B200这款GPU芯片,
而GB200而不是单一的GPU,
而是一种GPU计算系统,
以SuperPOD(超级节点)方式扩展大规模部署。
和美国关系好的那些人,
英伟达B200和GB200,
将在2024年第4季度,
和2025年第1季度,
陆续出货。
英伟达B300系列产品,
将按计划2025年第2季度至第3季度,
开始出货。

不仅如此,硬件变化还包括,
以前,“机内网络”高度集成,
GPU和交换机芯片集成在一起,
现在,交换机芯片单独出来了。
这些变化都归结在一个难点上,
到底怎么互联?
第一,一台服务器里有8张GPU(H100),
第二,增加到72张GPU(NVL72),
第三,将来还会塞288个,576个GPU,
第四,甚至再塞1152个GPU。
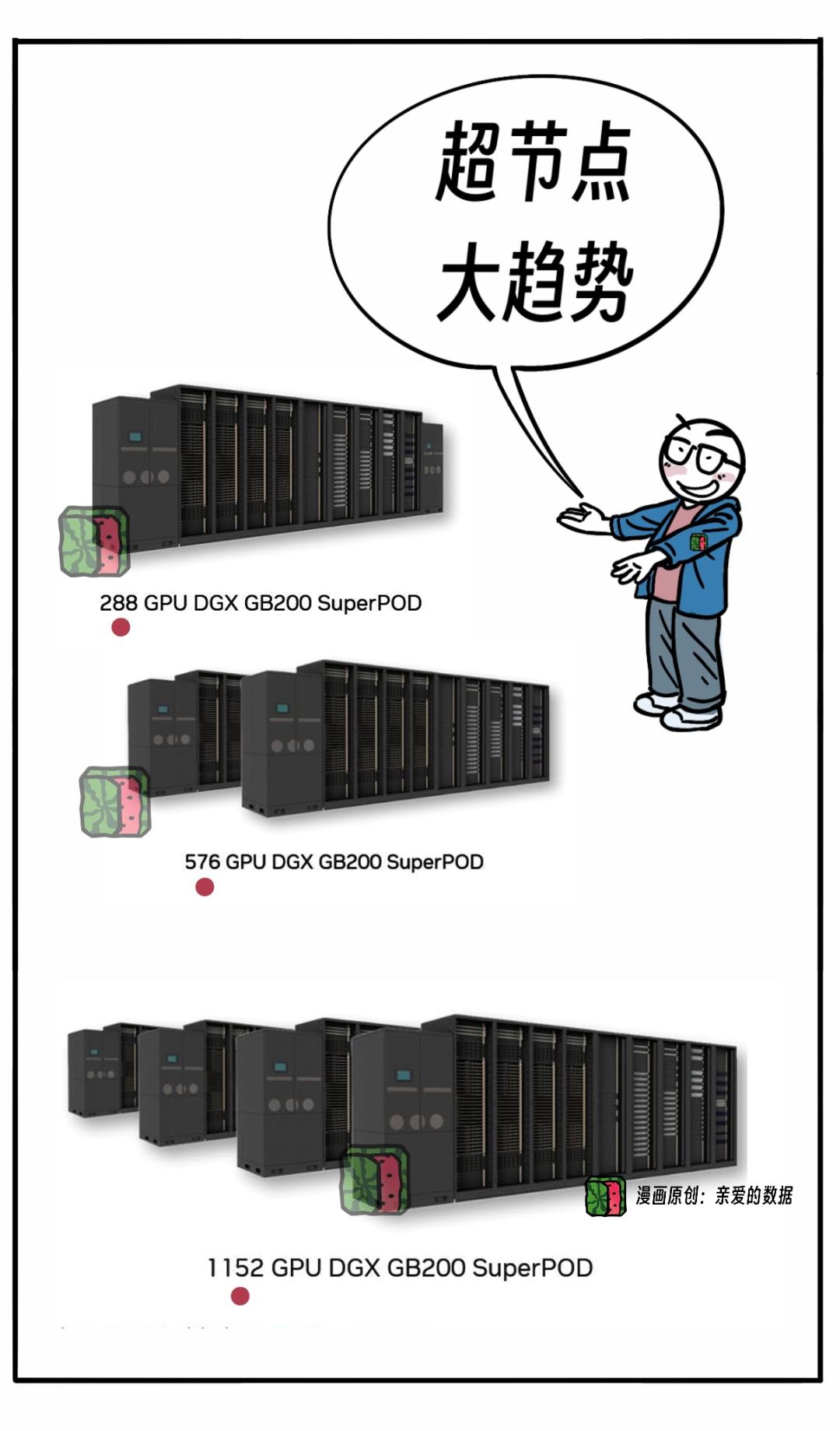
从NVL72开始,
英伟达提出让Scale up网络冲出服务器边界。
这样,NVL72网络的就在服务器外面了。
好消息是,
网速是快了,
更好消息是,
延续了机内比机外贵的“光荣传统”,
Scale up网络的价格,
也比Scale out网络贵了一个数量级。
谁不高兴利润高呢?
好好干活,
把钱赚了。
可是,别让英伟达一个人把钱赚了。
写到这里,
该总结一下了:
网络有变,钱多,速来。
(三)NVL72组网,数学题不会就是不会
硬件总会坏,没办法,
都想把GPU往死用。
前不久,Meta公司说1.6万卡GPU集群搞训练,
大概每隔2-3个小时就挂死一次,
这是什么概念?
我们假定任务重启耗时15分钟,
那这个占比就将近1/10。
当这个集群变成10万卡,
30分钟挂起一次,
15分钟解决故障,
白费50%的时间。
而且这个硬件故障率,
短时间内不会有根本性改变。
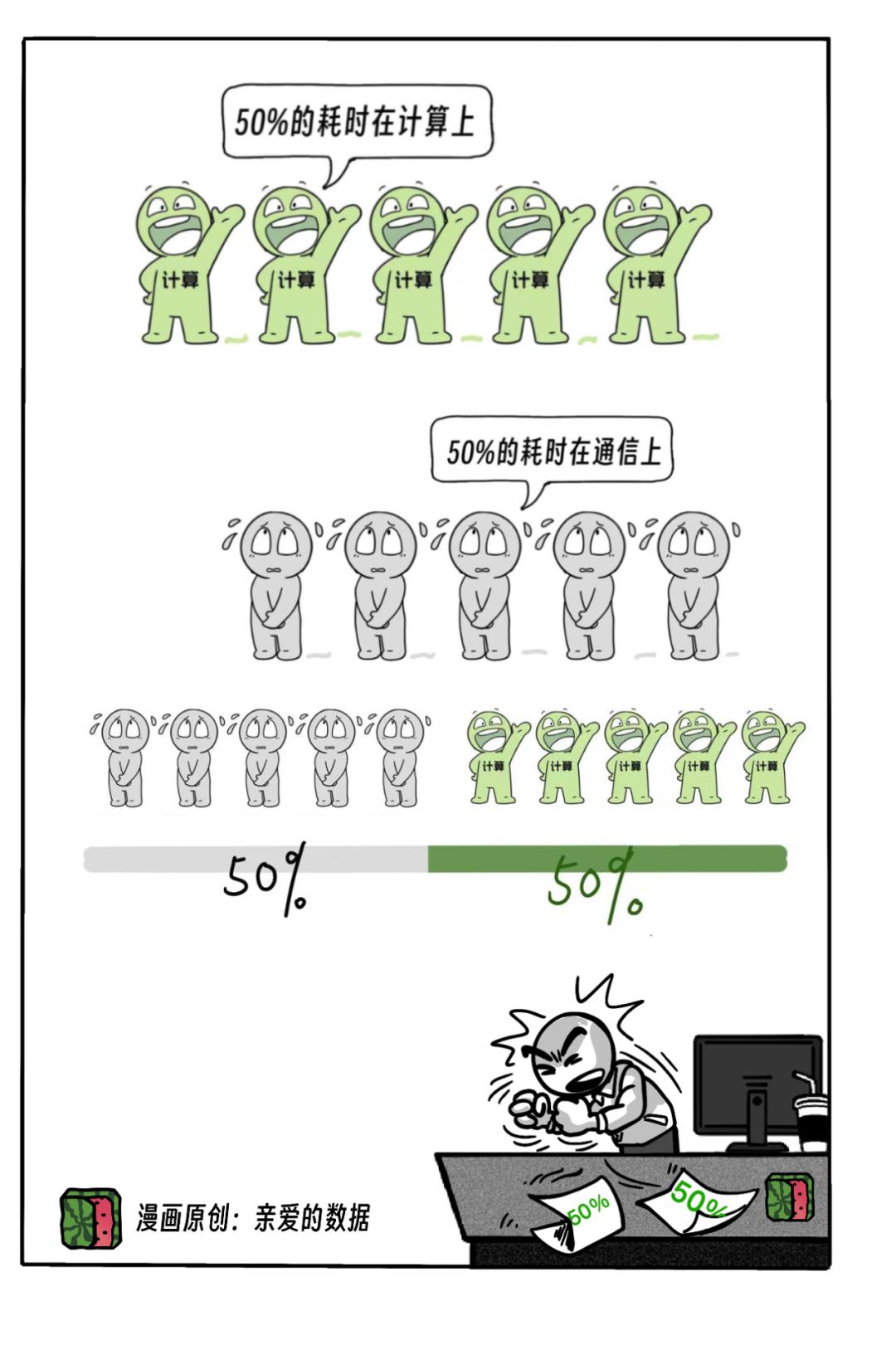
不过,有了超节点NVL72,
情况好转了一点,
NVL72里面,
是Scale up网络互联,
也就是超高速互联。
以前,
一个服务器里8张GPU,
1张GPU卡坏了,
整个服务器就挂了。
现在,
一个服务器里面有18张计算卡,
(也就是托架,英文Tray),
一张GPU卡坏了,
还有17个计算卡可以继续用,
故障范围变小了。
NVL72扩大成NVL576呢?
这么多设备,
网络肯定复杂了,
得考虑,
NVL72组网的架构怎么设计?
肯定需要多层的网络设计。
感觉进入谭老师我不擅长之处了。
NLV576作为一个超级大的节点,
我口算一下NVL 576的网络架构:
576=72x8
果然算错了,
正确的算法是:
576=36 X 16,
为什么呢?
因为设备数量超过一个机架(Rack)的容量,
就需要2级组网。
引入交换机,
用交换机支持多个机架之间的通信和数据传输,
而每个交换机的端口数有限。
网络在扩展,
但也会导致端口利用率的降低。
举个例子,NVL576由16台NVL36组成。
它的网络结构,需引入2级交换机,
一层NV Switch上面还要再加一层NV Switch。
NV Switch之间还需要互联,
占了一半端口。
也就是说,
不能所有的端口都连在GPU上,
留有端口连2级交换机,
所以,要空出来36个口,
让它们去连交换机。
复杂吧。
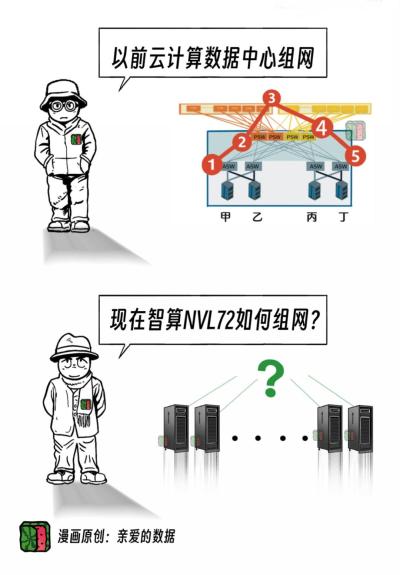
不过,花开两朵,各表一枝,
交换机多了,
客户要建更复杂的网络,
花更多的钱。
这里,用数学中的拓扑,
来分析节点之间的互联结构和路径优化。
阿里云智能集团研究员席永青告诉我一些细节:
“比如,模型训练时候的资源分布,
跟网络拓扑做一定的亲和性,
可以使训练效果更好。”
10万卡的网络的难题,
顶级卡规模团队训练必须要搞定,
目前最关心这个了,
是时候考验团队技术水平了,
大老板们可能会用这个技术难点做年终OKR。
写到这里,
故事基本讲完了,
若想理解更深,
需往前追溯“网络一战”。
(四)回顾 “网络一战”,胜负已分
在下手写网络“一战”之前,
作为一个科技科普作者,
我必须表达一下对以太网的崇敬,
尽管计算机经历了多次重大变革,
但以太网一直以来都在改进
对技术变革的适应性极强。
我今天讲的这段,
只是以太网历史长河中的一朵浪花。
浪花淘尽英雄,
不愧为世界上应用最广泛的网络技术,
以太网的发明者也说:
“将以太网设计为一个开放的、非专有的、
产业化标准的本地网络的意义,
甚至大于发明以太网本身。”
至于AI网络,
在4卡8卡的那个时期,
就需要高性能网络了,
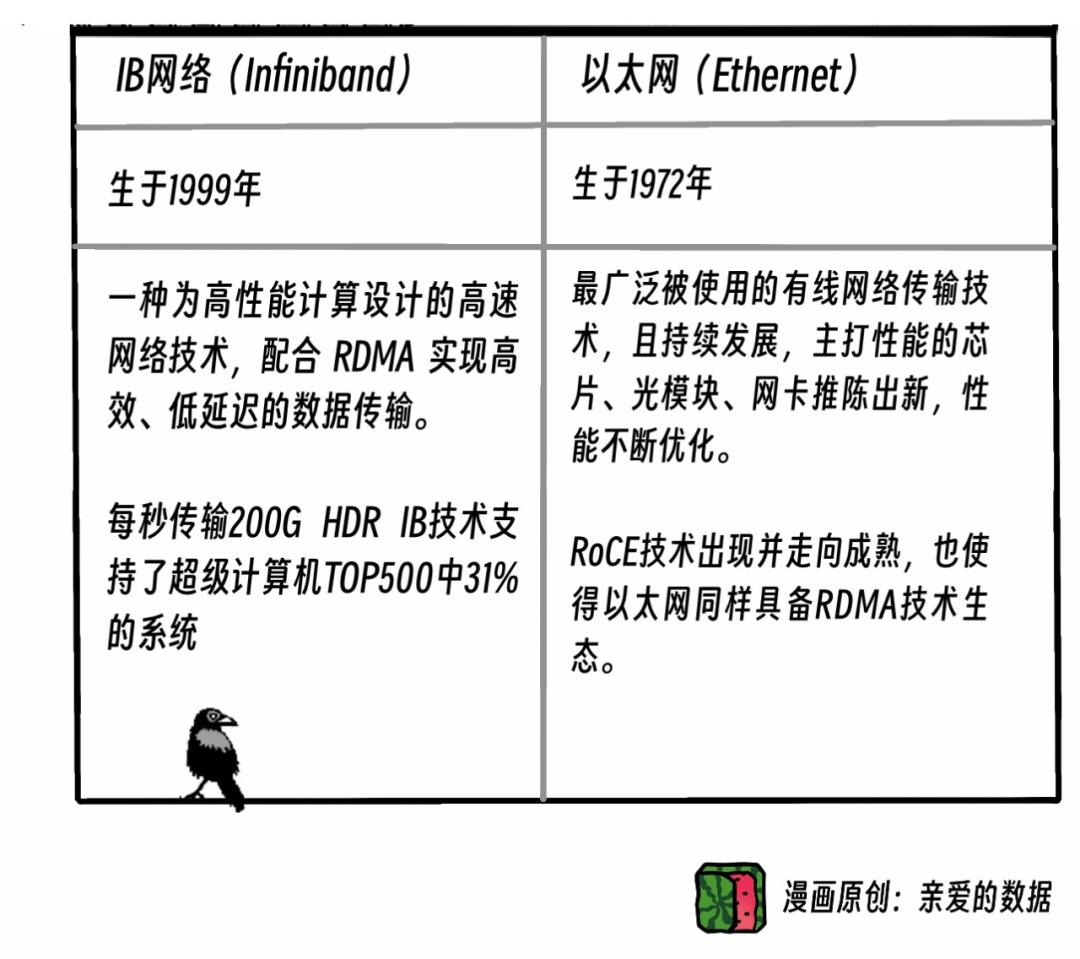
而且有两股技术力量在较量,
InfiniBand(IB)网络和以太网(RoCE)。

不用多说,
大家应该看出来我站哪边了,
从古至今,胜利从来都不是轻而易得的。
IB是英伟达买下了Mellanox公司,
进而获得了该技术。
我认为,IB挑战以太网,
是获得了一些先机。
但是先机不代表胜利。
IB帮英伟达赚到了大钱。
毕竟,IB这种网络是英伟达专有,
专有意味着,
专有了技术,
专有了设备及连接部件。
这样玩,肯定封闭了。
话说两头,封闭某种程度上确实赚钱,
但也会限制发展。
输赢不在一时,
经过几年激烈竞争,
以太网(RoCE)赢了。
谁叫人家以太网(RoCE)是开放标准呢,
可跑在任何以太网硬件(支持RoCE)上。
“任何”两个字语气加重。
想想换昂贵设备的成本,
语气还得再沉痛一些。
毕竟,贼船好上,不好下。
RoCE被视为在以太网的基础上,
实现了更高效的数据传输。
你也可以不理解RoCE的技术原理
简单说,以太网(RoCE)赢在开放,
朋友多,生态大。
其实竞争还是比拼了性价比。
虽然太网(RoCE)有暗坑,
对技术团队的要求也高,
但是,谁让人家主打一个性价比呢?
再讲一个错误的理解,
有人总说,英伟达这好那好,
对英伟达只会猛夸,
英伟达的IB网络也最好。
实际上,以太网(RoCE)在万卡规模,
已经暗暗赢了。
现在马上进入72卡GPU的时期,
网络“一战”的硝烟似乎没有消散。
我在写网络“一战”的时候,
我的观察是,
互联网自诞生之日起就主打一个开放,
就像两个人聊天,不能鸡同鸭讲,
不同厂商的设备之间,
也需要有“标准语言”来进行“连接”。
因此,一种组织应运而生,
帮大家一起合作,
毕竟,实力固然重要,
联合起来能更厉害,
接下来,我将讨论这种有影响力的联盟,
它在网络技术中如何发挥不可或缺的力量。
(五)激进的五大玩家
“网络二战”早就打响了第一枪,
战场就是Scale up网络。
新一轮网络技术之间的较量又开始了,
参与的玩家很多,
准确地说,他们是“非英伟达玩家”。
到底怎么玩呢?
假如每家都搞“私有化网络”,
场面有点尴尬,
不如这样,
还是基于以太网开放标准的改造,
既解决Scale up网络的难题,
也对抗英伟达一家独大。

以太网标准就像是制定了规则,
比如道路的宽度、车速的限制等,
保证不同公司的“车辆”都可以在这个“道路”上跑。
这个派系,依赖于以太网的基础设施,
不仅有实力的厂商非常多,
而且还有专门的联盟。
比如,超以太网联盟,
UEC, Ultra Ethernet Consortium。
就是一个由科技巨头组成的联盟,
创建了一个开放标准来对抗英伟达。
我再细数一下,
非常激进的五大厂商的玩法,
当然,他们都是UEC联盟成员。
第一,Meta公司。
LLAMA 3.1模型,
开源最好的模型,
坚定地选择以太网。
第二,AMD公司。
有人认为英伟达这好那好 ,
无人能抗衡。
其实,AMD的GPU实力也在积蓄,
而且,AMD也有类似NVLink的技术,
叫Infinity Fabric(IF),
但没有做类似于NV Switch这样专属技术。
而在基于以太网发展网络,
即IF over Ethernet。
这是另外一个故事了,
找机会再细聊。
第三,特斯拉公司。
马斯克特斯拉Tesla Dojo ,
发展出基于以太网的自定义传输协议(TTPoE)。
几个大公司都有自研协议,替代RoCE和NVLINK,
当然RoCE 自己也在提升。
有人批评特斯拉,说它是做车的,搞网络不擅长。
它家刚出道的时候,做车也不擅长,
看看今天什么局面。

第四,xAI公司。
马斯克xAI10万卡单集群网络,也基于以太网。
马斯克可能是第一个,
也是唯一一个,
自动驾驶和AI大模型智算知识产权都有的老板。
没办法,首富呗。
第五,阿里云公司。
阿里云是AI大模型网络顶配玩家,
数据中心早期入局者,
阿里云自研的通义大模型开源闭源通吃。
因此,阿里云得拿出来单聊,
他们近期还有一些大动作。
(六)各自为战 or 联合起来
大争之世,“联”合起来非常重要,
号召联合的前提是技术牛,
甚至说,技术牛,是联合各方力量的一种资格。

发起联盟,
基因和技术领先性都很重要。
阿里云是超以太网联能盟(UEC)
技术咨询委员会里唯一的中国公司,
也是网络开源操作系统SONiC创始成员中唯一的中国公司,
有开放标准联盟的基因。
而且,技术沉淀久。
ACM SIGCOMM这个学术会议,
是网络通信领域全球最具影响力的会议之一
论文录取率非常低,
其中网络架构的论文发表更难,
上一次该会发表的数据中心网络架构方向的论文,
还是2015年(谷歌Jupiter)。
阿里云在2019年在 SIGCOMM 上,
发表的首篇论文,
也是该顶会有史以来中国大陆企业“中”的第一篇。
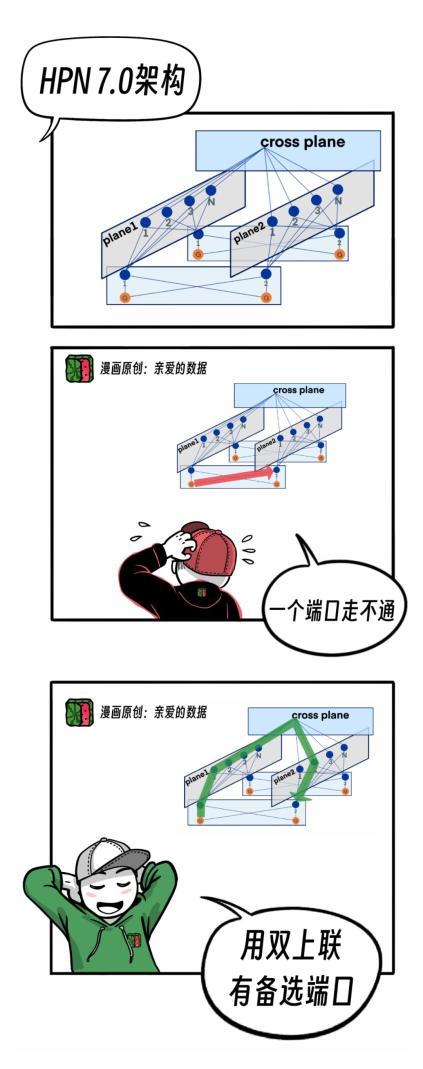
2024年,HPN7.0架构论文在 SIGCOMM 发表,
开启了智算数据中心网络架构的新范式。
通义大模型的底层也使用该架构。
这是阿里云基础设施里的一个法宝。

为此,我求教了阿里云智能集团研究员付斌章,
他告诉我,
对于超大规模的这种训练,
要求可靠性高,
HPN7.0架构如何来保证可靠性呢?
它有个独有的双上联技术。
在这个架构里,
每个网卡会出两个端口,
一个路径坏了,
可走另外一个路径。
否则如果这一个端口挂了,
这个任务就停掉了。
英伟达默认只有一个端口,
而阿里云(比如PAI灵骏产品),
也用上了双上联组网技术,
每个网卡的两个端口,
分别接到两个交换机上,
在连接出现故障时可自动切换,
保证网络可用性。
技术原理是两个端口对应两个平面,
如图所示。
学霸移步付斌章研究员还告诉我,
阿里云是全球最早做出51.2T这个容量的,
大规模商业用交换机。
我相信,从名字也可以看出来,
高通量以太网是在以太网这个公共组件上改造,
搞开放标准的联盟,
我猜想,他们的口号可能呼之欲出了:
全球伙伴(非英伟达玩家)联合起来,
打造智算网络的“安卓(Android)”生态。
实际上,他们的联盟愿景是,
基于开放、强大的以太网生态,
打造智算网络的技术底座,
满足Scale out和Scale up网络,
对性能、成本和可靠性的要求。
我认为,高通量以太网等于UEC加UAL的中国版。
(七)附加题:单聊UAL
天下网络,
合久必分,分久必合。
IB以太网之争刚刚谢幕,
以太网交换机市场又将迎来新战场。
蒙着一点神秘的面纱的UAL(Ultra Accelerator Link),
也加入了战局。
标准没有发布,
所以说,UAL蒙着神秘面纱。
10月30日,
UAL正式成立,新闻标题直接喊话英伟达
《UALink 联盟准备与英伟达NVLink竞争》
且UAL有九大董事会成员,
来势汹汹,
可惜没有博通。
大争之世,
到处纷争,
外部争,内部也争,
据“亲爱的数据”独家消息,
在UAL 联盟内部,已经改革了一次,
UAL Switch抛弃了“PCIE Switch” 道路,
也转向以太网,
这点还是相当有前瞻性,
Scale-up 网络规模越来越大,
我猜想,
可能某天就和Scale-out网络合了,
毕竟,成本和性价比才是发展的硬道理。
AI大模型莫不例外,
只有基于共同的以太网,
才有合的可能。
One more thing
开头我提到的那家知名大模型公司,
能不能亡羊补牢?
能补买NVLink,NVSwitch吗?
答案很悲剧,
不能。
虽然GPU算力部分一样,
但是设备在IO接口中,
没有NVlink的接口,
只有PCIe的接口。
(完)
更多阅读:
《作者直到最近才费劲弄清楚的……》
1.2.3.4.长文系列
1. 2. 4. 5. 6. 7. 8. 9. 10.11.12、漫画系列
1. 2. 3. 5. 6.AI安全
1.2.

个人观点,仅供参考继续滑动看下一个轻触阅读原文

亲爱的数据向上滑动看下一个
原标题:《对抗NVLink简史?10万卡争端,英伟达NVL72超节点挑起》

发布评论